What Is The QY-45Y3-Q8W32 Model? Separating Facts From Internet Hype
Jun 25, 2026


Few SEO topics create more confusion than crawl budget. Some people treat it like a critical ranking factor, while others completely ignore it.
And somewhere in the middle are website owners wasting time optimizing crawl budget on sites with 200 pages.
The problem is that crawl budget discussions often become overly technical very quickly.
Most articles explain it using vague definitions, complex terminology, and theoretical examples that do not help real businesses understand whether crawl budget even matters for them.
So let me simplify it.
Crawl budget is essentially the amount of attention search engines are willing to give your website.
Google has limited resources, but the internet contains billions of pages. Moreover, search engines cannot crawl everything endlessly.
So they make decisions, including:
That is your crawl budget. For some websites, it barely matters, while for others, it can quietly become a major SEO problem, especially when websites scale.
And today, as AI-generated content explodes across the internet, crawl efficiency is becoming even more important.
Because Google is dealing with an overwhelming amount of low-value pages, that changes how search engines allocate crawling resources.
Also, understanding crawl budget now matters less as a technical SEO buzzword and more as part of overall website quality and efficiency.
So, here I am to help you understand the relevance of crawl budget in 2026.
Stay tuned.

Crawl budget refers to the number of pages Googlebot is willing and able to crawl on your website within a given period.
So, Googlebot is Google’s web crawler. Its job is to discover pages, analyze content, and update Google’s index.
But Googlebot does not have unlimited time. As a result, every website receives a certain level of crawling attention based on multiple factors.
This includes:
So, think of crawl budget like a company managing limited resources. If your website helps Google crawl efficiently, more important pages get discovered faster.
However, if your website wastes resources on useless URLs, duplicate pages, and technical clutter, crawling becomes inefficient.
That can slow down indexing and visibility.
Google generally breaks crawl budget into two core concepts.
This refers to how much crawling your server can handle.
So, Google does not want crawling activity to overload your website. As a result, if a server becomes slow or unstable, Google may reduce crawl activity temporarily.
Moreover, several factors influence crawl capacity.
These include:
TBH, a fast, stable website usually supports more efficient crawling, while a slow website creates friction.
Crawl demand refers to how much Google actually wants to crawl your pages. Not every page on a website receives equal attention.
Google prioritizes URLs it believes are important.
As a result, you will see that pages with higher crawl demand often include:
Meanwhile, low-value pages may receive far less crawling attention.
That distinction matters. Because many websites accidentally create huge amounts of low-value URLs. And those pages can quietly drain crawl efficiency.

One of the biggest misconceptions in SEO is that every website needs to obsess over crawl budget.
That is simply not true.
For small websites, crawl budget is rarely a major issue.
So, the truth is, Google can crawl your site without problems if it has:
But things change at scale. Also, in my experience, large websites often create massive crawling inefficiencies.
In this context, examples include:
At that level, crawl management becomes much more important because Googlebot may waste significant resources crawling pages that provide little value.
And when that happens, important pages may not get crawled frequently enough.
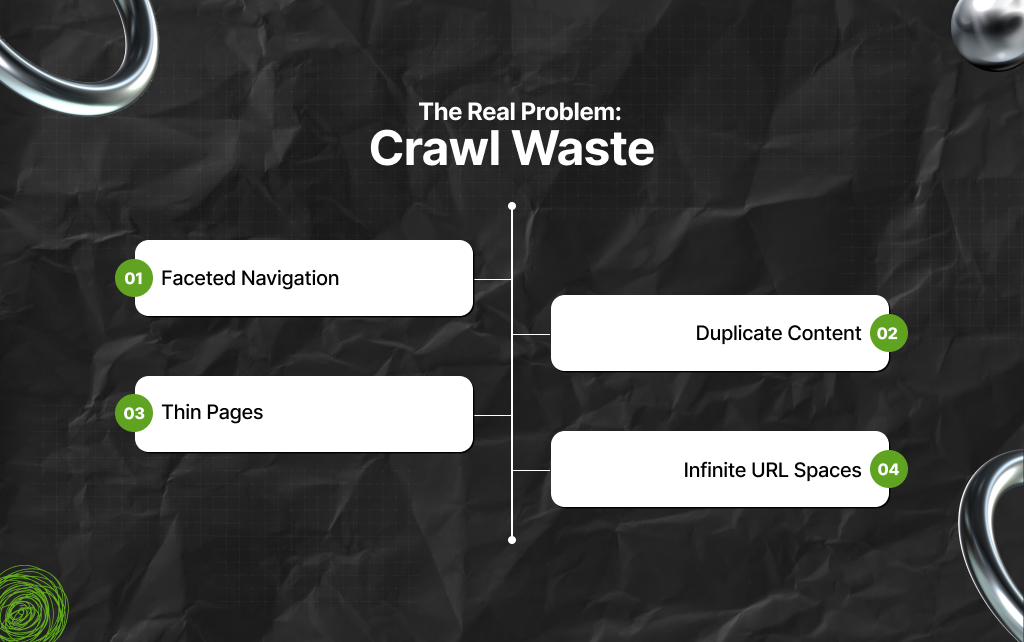
Most crawl budget problems are actually crawl waste problems.
So, the truth is, websites often generate huge amounts of unnecessary URLs. And Googlebot still spends time processing them.
That creates inefficiency.
As a result, the most common sources of crawl waste are:
So, eCommerce websites commonly create endless URL combinations.
In this context, examples include:
This can generate thousands or even millions of crawlable URL variations. Also, many offer little unique value.
Duplicate pages confuse crawling priorities.
In this context, examples include:
Additionally, Google may waste resources repeatedly crawling similar content.
Large websites often contain weak pages with very little value.
In this context, examples include:
Also, if too many low-value pages exist, overall crawl efficiency declines.
Some websites accidentally create endless crawl paths.
In this context, examples include:
These can become massive crawl traps. Moreover, Googlebot may continue discovering useless URLs endlessly.
Crawling and indexing are different processes.
Google first crawls a page. Then it decides whether the page deserves to be indexed.
However, any page can be crawled without being indexed. And sometimes pages are not crawled often enough to stay updated in Google’s index.
Moreover, this becomes especially important for:
As a result, if Google cannot efficiently crawl your important pages, indexing delays may happen. That can impact search visibility.
The internet is currently experiencing a content explosion.
AI tools allow websites to publish thousands of pages quickly. But more pages do not automatically create more value.
In fact, many websites are flooding search engines with:
As a result, Google now faces an enormous crawling challenge. The amount of indexable content online keeps growing rapidly.
That means Google must become more selective. This is why crawl efficiency matters increasingly.
Moreover, search engines want to spend resources on pages that appear valuable.
So, websites producing large volumes of low-quality URLs may eventually receive less crawling attention. That is where crawl budget intersects with overall site quality.

Not every indexing issue is a crawl budget issue. But some signals may indicate crawling inefficiencies.
And I’m here to help you understand the most common signs that indicate your site has crawl budget issues.
If high-value pages take too long to appear in search results, crawling frequency may be part of the issue.
Inside Google Search Console, some websites see many pages marked as “Discovered – currently not indexed,” or “Crawled – currently not indexed.”
This can sometimes indicate quality or crawl prioritization problems.
Log files can reveal where Googlebot spends its time.
So, some websites discover that Googlebot repeatedly crawls filter URLs, parameter pages, duplicate pages, old redirects, and thin content.
And this happens while important pages receive less attention.
Poor architecture often weakens crawl efficiency. As a result, pages buried deep inside a site may receive limited crawling attention.
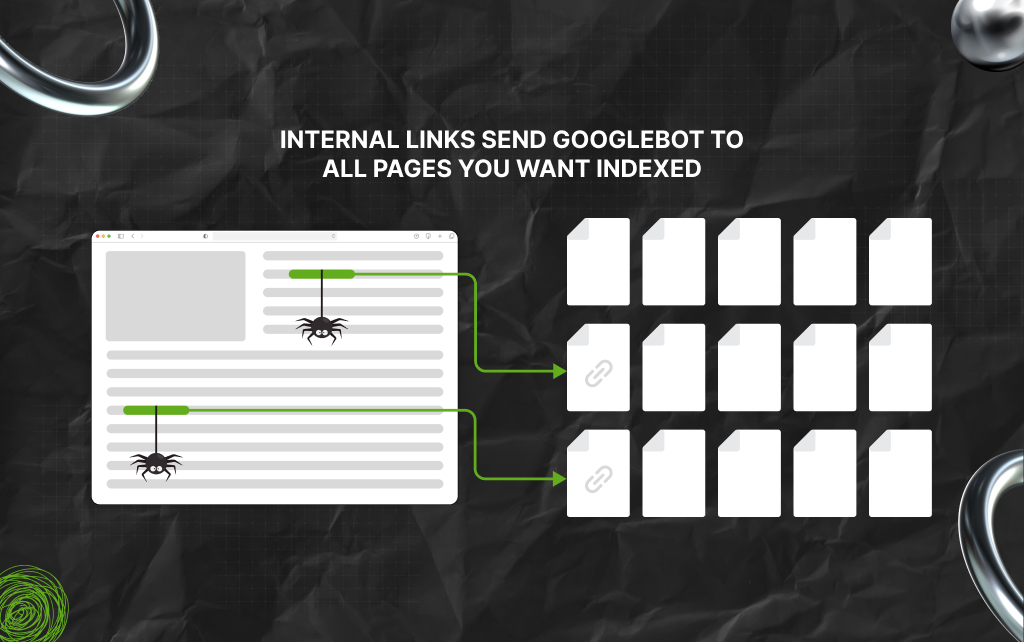
Internal linking strongly influences crawling behavior. Moreover, Google uses links to discover and prioritize pages.
As a result, pages receiving strong internal links usually appear more important. In contrast, weak internal linking creates problems, especially on large websites.
Good architecture helps Google understand:
As a result, the more important pages are to discover, the more efficiently Google can crawl them.
This is why flat, organized structures often perform better.
TBH, XML sitemaps can help, but they are not magic.
Sadly, XML sitemaps are often misunderstood. A sitemap does not force Google to crawl or index pages.
Instead, it acts more like a recommendation. Moreover, it helps search engines discover important URLs.
As a result, strong sitemaps typically:
Also, large websites especially benefit from clean sitemap management. But sitemaps alone cannot fix deeper quality problems.
Robots.txt allows websites to control crawler access. This can help reduce crawl waste significantly.
For example, websites may block:
But robots.txt requires caution.
Also, blocking important resources accidentally can create indexing problems. Many websites overcomplicate crawl control.
Sometimes the better solution is improving the site structure instead.

Many SEO checklists overcomplicate crawl optimization. In reality, the biggest wins usually come from improving efficiency.
Instead of auditing unnecessary pages, focus on:
So, the cleaner the site structure, the easier crawling becomes.
Important pages should receive strong internal links. This helps Google prioritize them naturally. And that is all you need to improve significantly.
Fast websites support better crawling. This is because technical stability matters – and the faster you understand, the better.
As a result, you need to reduce:
Only include URLs that deserve indexing. So, do not flood sitemaps with weak pages and ensure your site architecture is clean.
Quality affects crawl prioritization more than many people realize. As a result, strong websites naturally attract more crawling attention over time.
This is the part many technical SEO discussions ignore.
Google allocates more resources to websites it perceives as valuable. That means crawl budget is not only a technical issue.
Also, it is connected to quality.
As a result, websites are more likely to justify consistent crawling if they publish:
Meanwhile, websites producing endless low-value pages may struggle increasingly.
This becomes especially important now. Because Google is trying to manage massive amounts of repetitive AI-generated content.
Crawl budget discussions will likely become more important in the next few years. Not because the crawl budget itself is new.
But because the internet is changing.
Search engines now face:
As a result, Google must decide where to spend its resources. That means websites creating genuine value may benefit.
And websites generating huge amounts of low-quality pages may struggle more. Also, efficiency, trust, and content quality are becoming increasingly connected.
Moreover, crawl budget is often treated like an advanced technical SEO mystery. In reality, the core idea is simple: Google wants to crawl websites efficiently.
So, the trick is, the easier you make that process, the better. For small websites, crawl budget usually is not something worth obsessing over.
But for larger websites, poor crawl efficiency can quietly create serious visibility problems.
And in today’s search environment, where AI-generated content is flooding the web, crawl prioritization matters more than ever.
Additionally, the websites most likely to succeed long term are not the ones publishing the most pages since they are the ones creating the clearest value.
Because ultimately, crawl budget reflects something bigger.
Search engines are constantly deciding what deserves attention. And websites need to prove they are worth crawling.
Barsha is a seasoned digital marketing writer with a focus on SEO, content marketing, and conversion-driven copy. With 8+ years of experience in crafting high-performing content for startups, agencies, and established brands, Barsha brings strategic insight and storytelling together to drive online growth. When not writing, Barsha spends time obsessing over conspiracy theories, the latest Google algorithm changes, and content trends.
View all Posts

What Is The QY-45Y3-Q8W32 Model? Separating F...
Jun 25, 2026
Your HR Team Can Design A Stunning Event Post...
Jun 25, 2026
Multi-Model AI Video Generation: Generate Pro...
Jun 24, 2026
Spotify Unblocked: Why Spotify Gets Blocked A...
Jun 22, 2026
Colorizing Old Photos With AI: A 2026 Guide T...
Jun 20, 2026